This blog post series is about my attempt to implement The Web After Tomorrow that Nikita described in his blog post back in 2015.
This part is about some ideas I had to solve the performance challenge that was described in part 1.
Maybe the quickest fix would have been to try to only load datoms which are relevant for the current UI state. This idea is also part of Nikita's proposed solution:
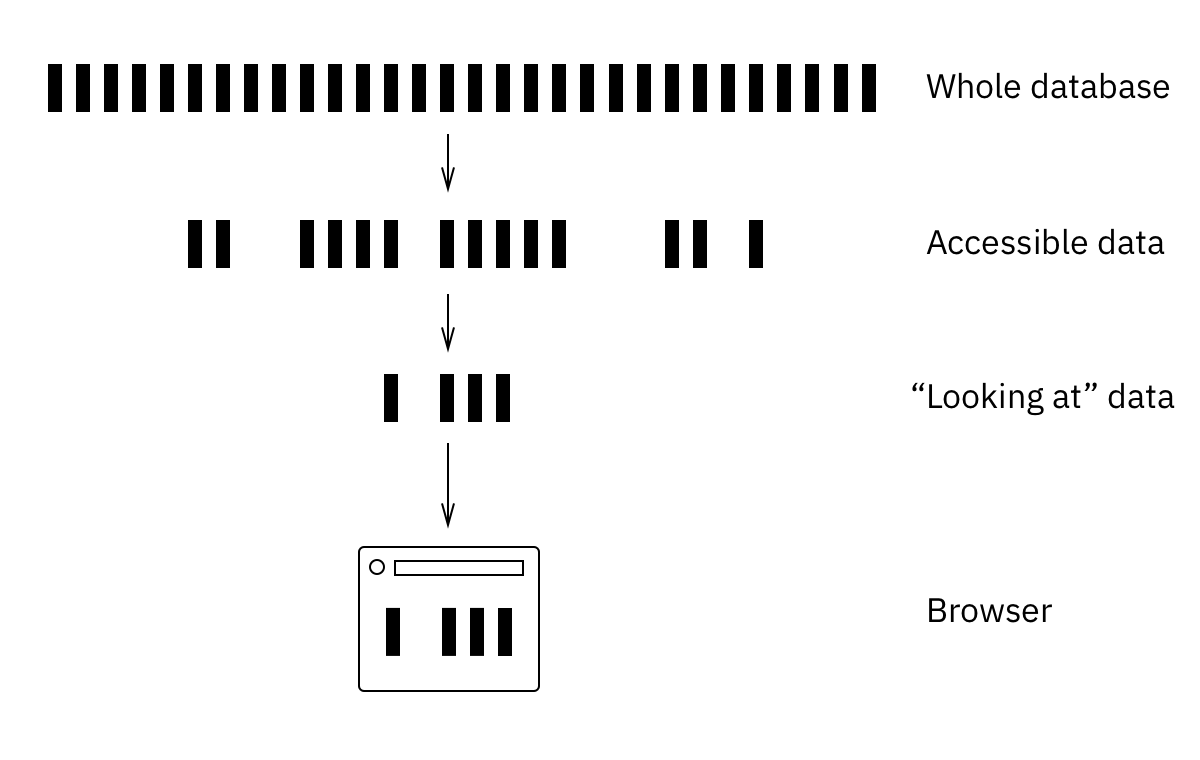
(source: http://tonsky.me/blog/the-web-after-tomorrow/)
While this is certainly doable, it increases the accidentally complexity, at least in our case. Our DataScript queries had access to the full database portion of the user, this is the layer "Accessible data" in the illustration above. Therefore nothing needed to be fetched from the "Whole database" in advance to ensure that a query will "see" everything it needs to yield the correct result.
However our performance challenge was that the amount of "Accessible data" for a lot of our users had grown too big. Therefore we need to make a change to only load the relevant data for the current UI state, which is the "Looking at data" in illustration above.
The "Looking at data" is only a subset of the "Accessible data" (which is a subset of the "Whole database"). You could also say that the "Looking at data" is derived from the "Accessible data" by applying a filter function for example. Another way would be to execute a database query (SQL, datalog etc.) to the "Accessible data" that yields the "Looking at data". In the context of a database this is often called a view. These views need to be kept up to date as soon as relevant data is transacted into the database. This tends to cause performance challenges. That's why there are a lot of optimizations available for this topic (like materialized views for example).
I do not want to dive deeper into this topic here. I only like to mention a few interesting approaches:
While all these topics are super interesting to me, they have one thing in common:
They are probably not the core of your business, except your company is offering a database product or service. Thereby you end up spending a lot of effort building a half-backed database, instead of focusing on improving the app or service that your company is offering.
Another way would have been to switch back to a "classic" REST API. This would have mean that we need to write custom logic to mimic the behaviour of our current real-time web app. A few examples:
As developers we have grown to like the automatic real-time behaviour of our web app. We just need to transact a change to Datomic and the UI of the affected user(s) will reflect this change.
To notify the user that we have posted his story, the server transacts the date of execution to the database entity that represents this scheduled story post. The new datoms are pushed to the browser of the user and are added to his local Datascript database. This triggers a re-execution of the corresponding datalog queries and this causes that the affected React UI elements are re-rendered. The user then sees the corresponding notification UI about the successful story post. Also other parts of the UI like the amount of remaining story posts updates automatically. In non real-time web apps this is often inconsistent, most of us have probably seen some messenger app, where the unread message icon does not disappear, after you have opened the new message(s). Only a page reload makes the unread message icon go away.
Instead of loading the datoms, another interesting idea is to provide the front-end with access to the database index. It would only cover the datoms, which are owned by the user (the "Accessible data"). Datomic's database index is implemented with a data structure that is similar to the persistent immutable data structures of Clojure. Both are tree data structures, but the one of Datomic must have way more entries per node to compensate the IO latency, similar to a B-Tree index of a relational database. Due to the immutable nature of this data structure it could be cached without any complex invalidations. This caching could also be done in the browser, whereby it would become something similar like a Datomic peer. Regrettably, Datomic's closed-source model makes this direction impractical.
An alternative is the so-called Hitchhiker Tree, which is open-source and offers similar characteristics like the Datomic index data structure. Transit JSON could be used as storage format, so that the browser can read it directly (Datomic is using the Fressian format).
However in the end you would run into the same issue like described above that you implement a half-baked database, which is a huge distraction from the core of your business. Another limitation is that the XHR request in the browser is asynchronous (the synchronous version is deprecated). To be able to fetch more index segments via XHR requests the DataScript API would need to become asynchronous too. And this would also change the developer experience a lot, since the entity API would not be practical anymore.
There is no doubt that GraphQL is in vogue nowadays and it has been adapted by many organizations already. Despite the good ecosystem (there is even a Clojure GraphQL lib) and tools which are available for GraphQL, it still means a lot of effort to implement a GraphQL back-end. Especially for a small developer team (like ours) this can become a huge burden. Therefore I thought about, if we would pick the optimal trade-offs for our small company, if we would adopt a technology like GraphQL (or a similar one like the EDN Query Language).
For that reason the next part of this blog post series will be about reconsidering some common trade-offs of modern web development. Picking different trade-offs can yield huge productivity gains for small teams of full stack developers, which do not have a split between front-end and back-end developer teams.
